在数据驱动的时代,掌握Java爬虫技术能让你高效获取网络信息。本文将带你全面了解Java爬虫的核心技术与实践方法。随着大数据和人工智能的快速发展,网络爬虫已成为获取数据的重要手段之一。Java凭借其稳定性、跨平台性和丰富的生态系统,在网络爬虫开发领域占据重要地位。无论你是想爬取电商网站的商品信息,还是需要收集新闻网站的最新资讯,Java都能提供强大的支持。
Java爬虫框架比较与选择
主流Java爬虫框架功能对比
目前Java生态中有多个成熟的爬虫框架可供选择,每个框架都有其独特的特点和适用场景。Jsoup是最轻量级的HTML解析库,特别适合处理静态网页内容,它的API设计简洁,学习曲线平缓。HttpClient则是一个功能强大的HTTP客户端库,可以处理各种复杂的HTTP请求和响应。对于需要爬取动态网页的场景,Selenium WebDriver是一个不错的选择,它能够模拟浏览器行为,完美解决JavaScript渲染的问题。
2023年Java爬虫最新技术趋势显示,WebMagic框架因其模块化设计和良好的扩展性越来越受欢迎。它提供了简单易用的API,同时支持分布式爬取和断点续爬等高级功能。另一个值得关注的框架是Apache Nutch,它是一个成熟的网络爬虫系统,适合构建企业级的搜索引擎。
如何根据项目需求选择合适的框架

选择爬虫框架时需要考虑多个因素。如果你的项目主要是爬取静态网页并进行简单的数据提取,Jsoup可能是最高效的选择。当遇到如何使用Java爬取动态网页这样的需求时,就需要考虑Selenium或PhantomJS这样的工具。对于大规模分布式爬取任务,WebMagic或Nutch提供了更好的解决方案。
性能也是重要的考量因素。在Java爬虫和Python爬虫哪个效率高的比较中,Java通常表现出更好的性能,特别是在处理高并发请求时。但Python的Scrapy框架在某些场景下可能开发效率更高。因此,如果你的团队主要使用Java技术栈,选择Java爬虫框架可以更好地与现有系统集成。
解决Java爬虫开发中的常见问题
在实际开发中,开发者经常会遇到各种挑战。Java爬虫如何避免被封IP是最常见的问题之一。有效的解决方案包括:设置合理的请求间隔、使用代理IP池、模拟真实用户行为(如设置User-Agent)、遵守robots.txt协议等。此外,还可以考虑使用分布式爬取策略,将请求分散到多个IP地址。
另一个常见问题是处理反爬机制。现代网站采用了各种技术来阻止爬虫,包括验证码、行为分析、请求频率限制等。应对这些挑战需要综合运用多种技术,如使用OCR识别验证码、模拟鼠标移动轨迹、动态调整请求频率等。
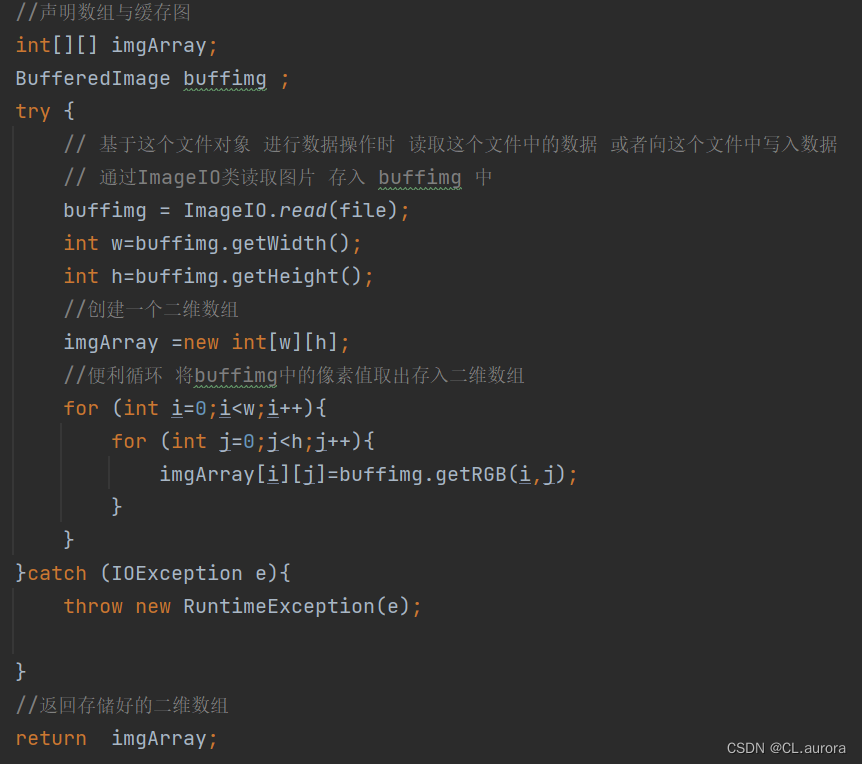
数据存储和处理的效率也是需要考虑的问题。对于大规模爬取任务,建议使用数据库批量插入、内存缓存等优化手段。同时,合理设计数据模型和索引可以显著提高后续数据查询和分析的效率。
Java爬虫实战案例分析
让我们通过一个实际案例来演示如何使用Java构建一个完整的爬虫系统。假设我们需要从某电商网站爬取商品信息和用户评价。首先,我们选择WebMagic作为爬虫框架,因为它提供了良好的扩展性和易用性。
第一步是分析目标网站的结构,确定需要爬取的URL模式和数据字段。然后,我们创建一个Spider类来定义爬取逻辑。为了提高效率,我们实现了多线程爬取,并设置了合理的请求间隔以避免被封禁。对于动态加载的内容,我们使用Selenium WebDriver来模拟浏览器行为。
在数据存储方面,我们使用MySQL数据库,并设计了优化的表结构。为了提高性能,我们实现了批量插入和连接池管理。为了应对可能的故障,我们还实现了断点续爬功能,确保在程序异常终止后能够从上次中断的位置继续爬取。
这个案例展示了Java爬虫开发的完整流程,从需求分析到系统设计,再到具体实现和优化。通过这个案例,我们可以看到Java爬虫技术在数据采集方面的强大能力。
现在就开始你的Java爬虫项目吧!
通过本文的介绍,相信你已经对Java爬虫技术有了全面的了解。无论是框架选择、常见问题解决还是实际项目开发,Java都提供了丰富的工具和解决方案。随着技术的不断发展,2023年Java爬虫最新技术也在不断演进,为开发者带来更多可能性。
无论你是想构建一个小型的个人数据采集工具,还是开发企业级的大规模爬虫系统,Java都能满足你的需求。现在就开始动手实践吧,从简单的项目开始,逐步掌握更高级的技术和技巧。记住,实践是最好的学习方式,只有通过实际项目的磨练,你才能真正掌握Java爬虫开发的精髓。
版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。